Pre-Trade Market Signal Briefing System is a course capstone project I implemented during Maven’s Building Agentic AI Applications with a Problem-First Approach.
The project used a market-news briefing use case to explore how LLM workflows can support time-sensitive research. The goal was not to build a trading product or provide financial advice, but to design and prototype a controlled AI system that could fetch market news, extract canonical market events, reduce duplicate catalyst signals, route direct and indirect candidates, and generate grounded ticker-level briefings.
This was a team capstone project. My contribution focused on the technical implementation of the prototype and live demo, building the FastAPI backend and React frontend that connected the LangGraph workflow from news ingestion to briefing generation and evaluation. I also contributed to the architecture decisions around where deterministic logic was safer than LLM reasoning, how to reduce unnecessary model calls, and how to keep the workflow observable enough to debug.
From fragmented news to catalyst briefings
Active traders often need to move through several sources before understanding whether a market event matters: news feeds, charts, analyst notes, company updates, macro events, and fragmented alerts.
The issue is not only access to information. The issue is synthesis under time pressure.
News aggregators collect headlines, but still leave the interpretation to the user. Rule-based alerts can notify traders when predefined conditions are met, but they do not understand context. Static models can capture historical patterns, but they are less suited to live qualitative news.
The capstone explored a different layer: an AI-assisted research workflow that sits between raw market information and the human decision. The system does not decide what to trade. It helps structure what changed, which watched ticker may be affected, whether the catalyst is fresh or repeated, and what uncertainty remains.
The difficult part was not making the LLM summarize an article. That is the easy part. The difficult part was deciding what deserved to become a briefing in the first place.
A useful market briefing has to be fresh, grounded, concise, tied to the correct ticker, and careful about uncertainty. If the system repeats old news, overstates weak relationships, routes an event to the wrong company, or generates unsupported financial language, it becomes another source of noise.
System architecture
The system starts from a watchlist and recent market news. It fetches company-specific news and broader cross-impact news when the iteration requires it. It then extracts canonical events, filters stale or low-value information, checks whether the catalyst has already been seen, routes direct or indirect candidates to watched tickers, and generates a structured briefing.
The architecture combines deterministic workflow logic with LLM-based reasoning.
- Deterministic code handles the parts that need consistency: freshness filtering, URL deduplication, direct routing, ledger updates, graph traversal boundaries, state persistence, and compliance cleanup.
- The LLM handles the parts that require language understanding: event extraction, synthesis, grounding checks, and concise explanation.
This separation was central to the project. The model was not used as one large black box. It was placed inside a workflow where each step could be inspected, optimized, and evaluated.
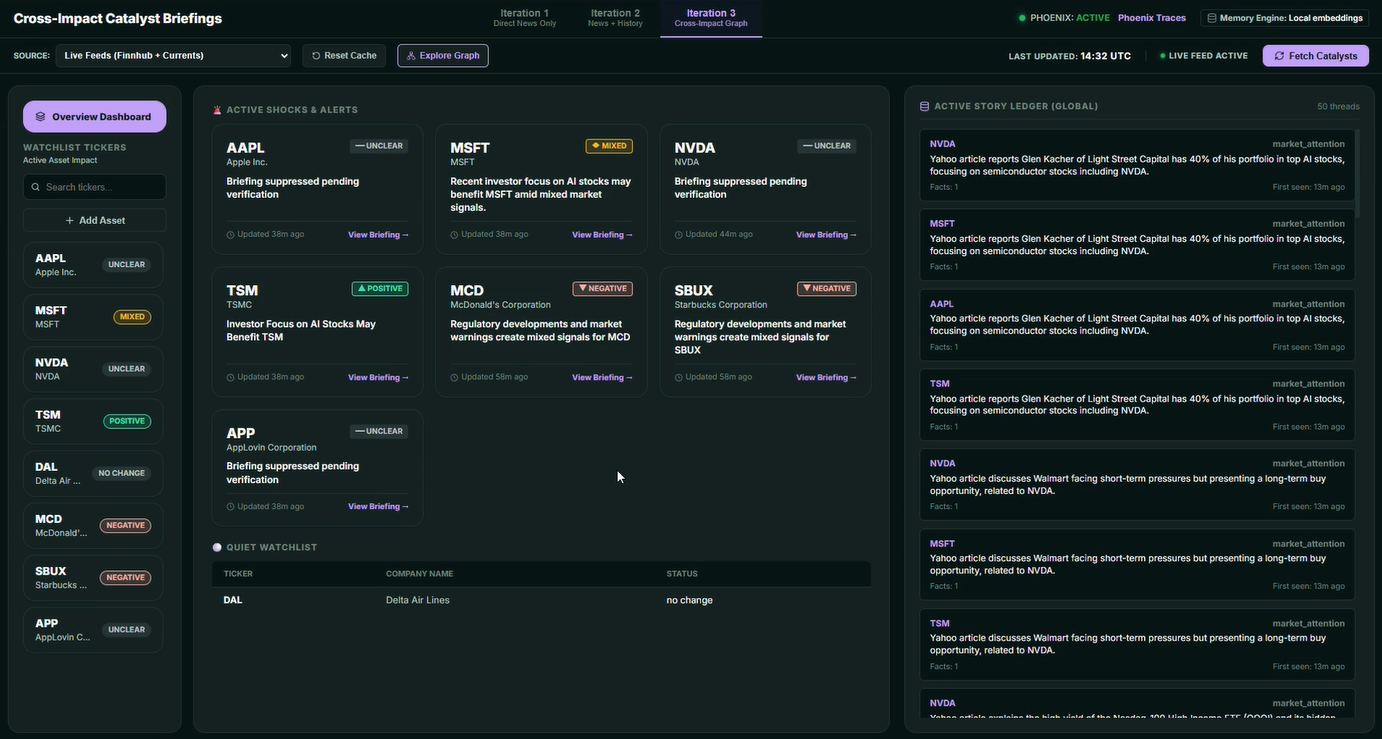
The prototype was built as a local web application: a FastAPI backend running the LangGraph workflow and a Vite/React frontend for watchlist controls, pipeline execution, graph expansion actions, and run-result inspection.
The workflow evolved across three iterations.
Iteration 1 — Direct per-ticker catalyst briefing
The first iteration focused on the most controlled version of the problem: direct company news.
The system started from a watchlist, fetched company news for each ticker, filtered for freshness, extracted events from the articles, grouped related information, and generated one grounded briefing per ticker.
This created the first version of the core flow:
watchlist → fetch → extract with direct focus → direct routing → assign new catalysts → ticker buckets → per-ticker synthesis → compliance
The aim was to build a reliable foundation before adding memory or broader relevance detection. The system needed to prove that it could fetch recent news, identify the actual catalyst, avoid obvious noise, and produce a concise briefing grounded in the source.
Performance and latency were already part of the design. A real-time briefing system cannot afford to spend model calls on stale articles, duplicated URLs, or empty ticker paths. The first workflow therefore prioritized filtering and deduplication before the LLM step.
This first version proved the basic briefing loop, but it also exposed an important limitation. Iteration 1 does not read or write the catalyst ledger, so repeated coverage can still be treated as fresh information. That became the reason for the second iteration.
Iteration 2 — Catalyst memory and story deduplication
The second iteration introduced the catalyst ledger. In this project, memory was not used for personalization. It was used as product state.
The system needed to know whether a new article represented a new catalyst, a duplicate of an existing catalyst, or a meaningful update to a story already seen.
This moved the workflow from article-level processing to catalyst-level tracking. Each extracted event was compared against live ledger entries for the same ticker and event type. Exact article repeats were treated as duplicates, same-thread events with new facts updated the ledger entry, same-thread events without new facts were suppressed, and below-threshold events created new catalyst entries.
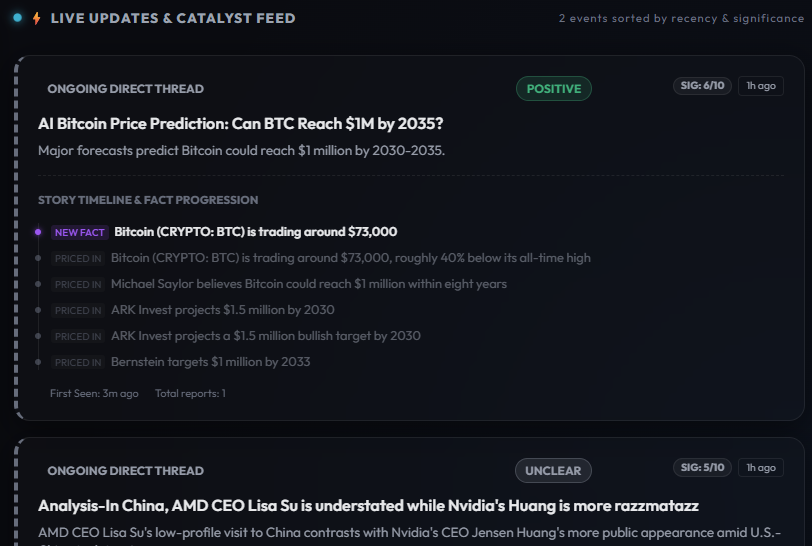
This made the product logic much stronger. The system was no longer only checking whether an article was relevant. It was checking whether the story had changed.
The ledger also introduced new cost and latency tradeoffs. Deduplication uses local embedding-based similarity, with deterministic lexical similarity as a fallback when embeddings are unavailable. The ledger is scoped by iteration and expires entries after one day, keeping memory useful without turning it into an open-ended retrieval layer.
This iteration made the briefing workflow less noisy and closer to how a real market assistant would need to behave.
Iteration 3 — Cross-impact catalyst routing
The third iteration expanded the system beyond direct company mentions.
A company can be affected by news even when the article does not name it. A supplier disruption can affect a manufacturer. A semiconductor constraint can affect AI infrastructure companies. A logistics event can affect retailers. A geopolitical event can affect companies through exposure to a region, commodity, or supply chain dependency.
This is where traditional ticker alerts are weakest.
It is also where an unconstrained LLM becomes too permissive. A model can often produce a plausible explanation for why an external event might affect a company, even when the relationship is weak or speculative.
To control this, the third iteration introduced an exposure graph.
The graph encoded relationships between watched tickers, public and private companies, sectors, suppliers, commodities, geographies, policies, routes, risks, and themes. The system could expand beyond direct company news, but only through bounded graph paths.
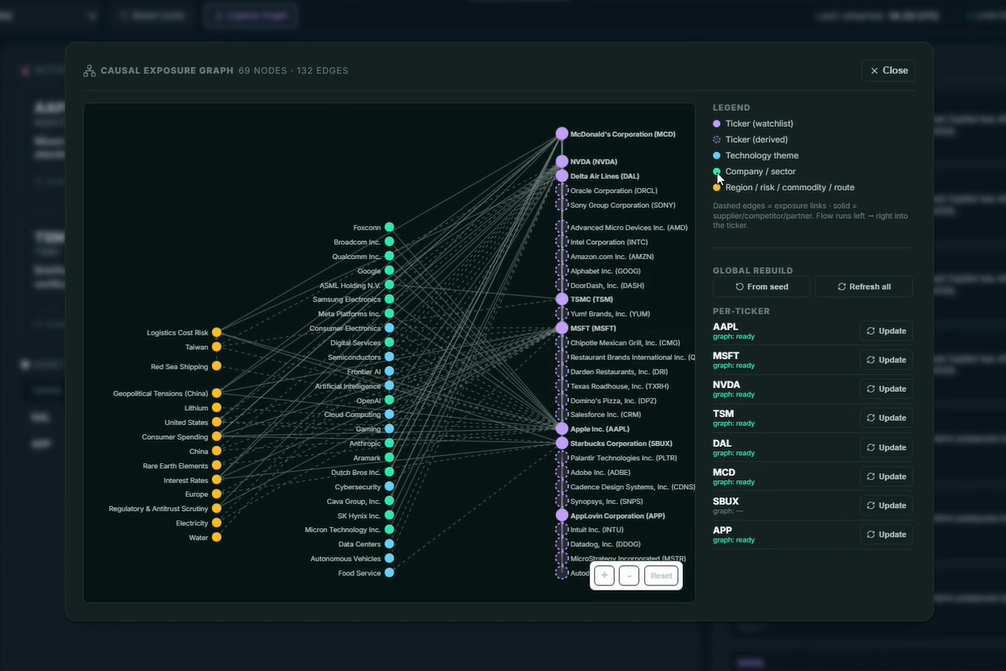
No exposure path meant no indirect briefing. This made the system less magical, but more credible. The LLM could explain a relationship, but it could not invent the relationship from scratch.
Cross-impact discovery also increased the performance and latency challenge. Broader retrieval and graph traversal create more candidate events before synthesis. The design therefore had to control graph depth, prioritize stronger paths, and stop weak indirect claims before they reached the briefing step.
This iteration changed the project from a summarization workflow into a relevance-routing system.
Evaluation and reliability
The course required each iteration to consider performance, cost, latency, optimization, guardrails, and evaluation. In the implementation, those concerns became practical decisions about when to call an LLM, when to use deterministic logic, and how to trace failures through the workflow.
That was important for this use case because a market briefing system can fail while still producing fluent text.
- A briefing can be well-written but stale.
- It can mention the right company but describe the wrong catalyst.
- It can identify a real event but repeat something already seen by the ledger.
- It can route a broad external event through a weak graph path.
- It can pass as fluent text while failing the actual product requirement.
For this reason, evaluation focused on the main failure modes of the workflow: structured output validity, ticker routing, duplicate detection, update detection, source grounding, freshness, cross-impact path validity, compliance language, latency, and LLM call usage.
Some checks could be deterministic, such as output structure, source presence, freshness window, duplicate rate, and banned language. Other checks required judgment, such as briefing usefulness, grounding quality, and whether an indirect relationship was strong enough to show.
The most important evaluation idea was that the system should not only be judged by the briefings it produced. It should also be judged by the briefings it correctly avoided producing. For this kind of product, silence can be the correct output when there is no fresh, grounded, and relevant signal.
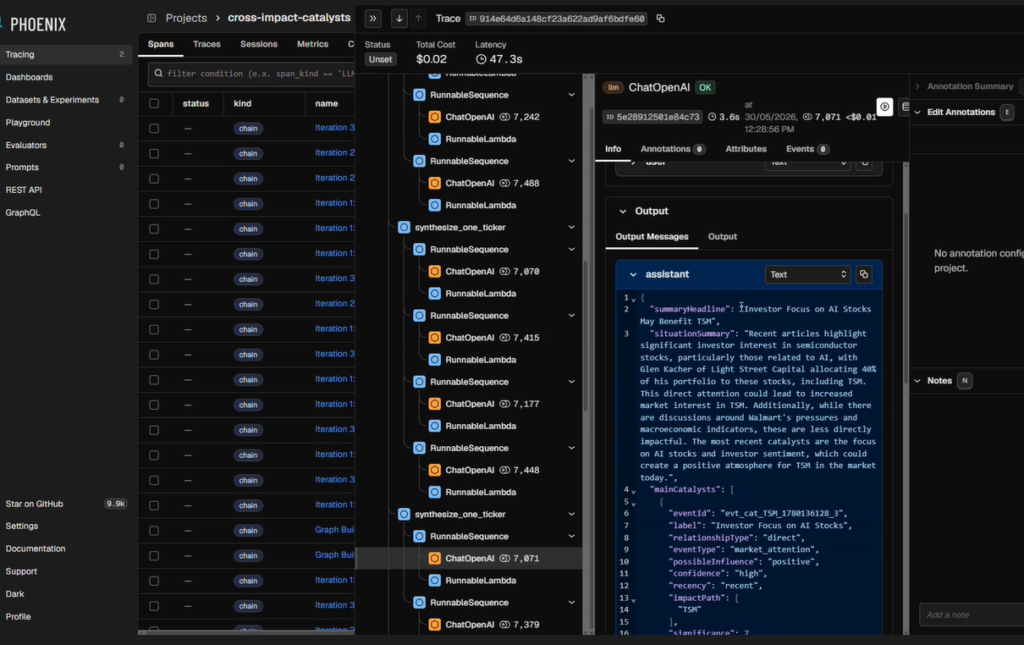
We instrumented the workflow with Arize Phoenix so the prototype was not only producing outputs, but exposing how those outputs were produced. This made it possible to inspect the sequence of LLM calls, inputs, outputs, latency, and intermediate decisions across the flow. For this kind of system, observability matters because a fluent final briefing is not enough: when something goes wrong, the builder needs to know whether the issue came from news ingestion, event extraction, ledger deduplication, routing, or final synthesis.
Prototype outcome
The final prototype was a local web application for running and inspecting the briefing workflow.
From the frontend, the user could manage a watchlist, trigger the pipeline, inspect the latest run, and review the generated ticker-level briefings. The FastAPI backend handled the LangGraph workflow behind it: news ingestion, event extraction, catalyst deduplication, direct and indirect routing, briefing synthesis, compliance cleanup, and evaluation checks.
The prototype demonstrated the three design iterations in one system. The first version could generate grounded briefings from direct company news. The second added catalyst memory, so repeated coverage could be suppressed or treated as an update rather than a fresh signal. The third expanded the routing logic to indirect events through the exposure graph, making it possible to connect broader market news to watched tickers without letting the model invent unsupported relationships.
The most useful result was not the final text of the briefing by itself. It was the controlled workflow around it. Each run produced outputs that could be inspected through the frontend and traced in Phoenix, making it possible to understand where a briefing came from and where the system might have failed.
The project showed that the hard part was not making an LLM summarize financial news. The hard part was building the product logic around the model: filtering what enters the workflow, preserving catalyst state, constraining indirect relevance, managing latency and LLM calls, and evaluating when the correct output should be no briefing at all.
Github Repo: [View code on GitHub]